The Growth and Android teams are both thinking about a new type of structured task for use in their "suggested edit" feeds. The task would involve newcomers adding images to articles that don't have any.
- For Android, it would likely be that a user is presented with an image and asked if it is appropriate for illustrating a given article.
- The core use case is that article X in English has a lead image, but does not have a lead image in Hindi. So we ask a user who speaks both English and Hindi to verify that it is ok to copy the lead image from English to Hindi.
- A secondary use case is to copy an image from article X to related article Y, whether within the same language or between languages.
- For Growth, it would likely be that a user is on an article, and receives a suggestion for an image to illustrate that article.
This task is for @Miriam to attempt a simple approach for suggesting these article/image pairs using Wikidata and interlanguage links (and whatever other methods she recommends). The output might look like:
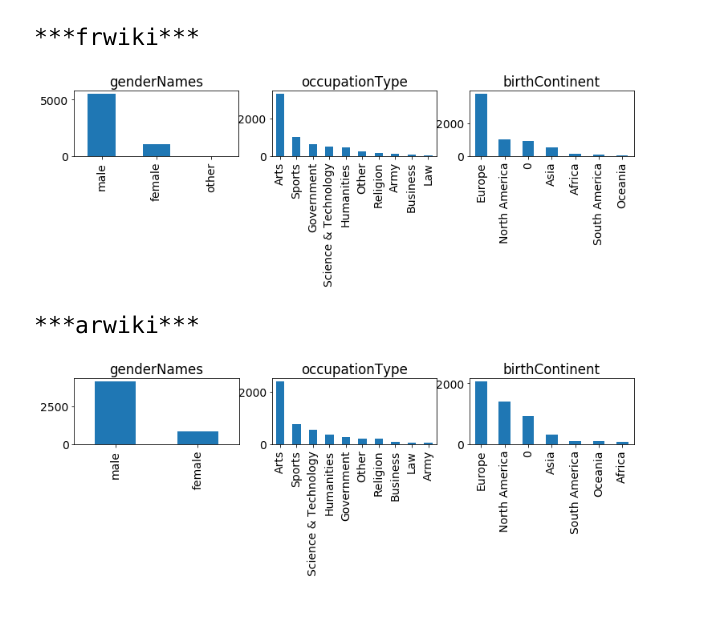
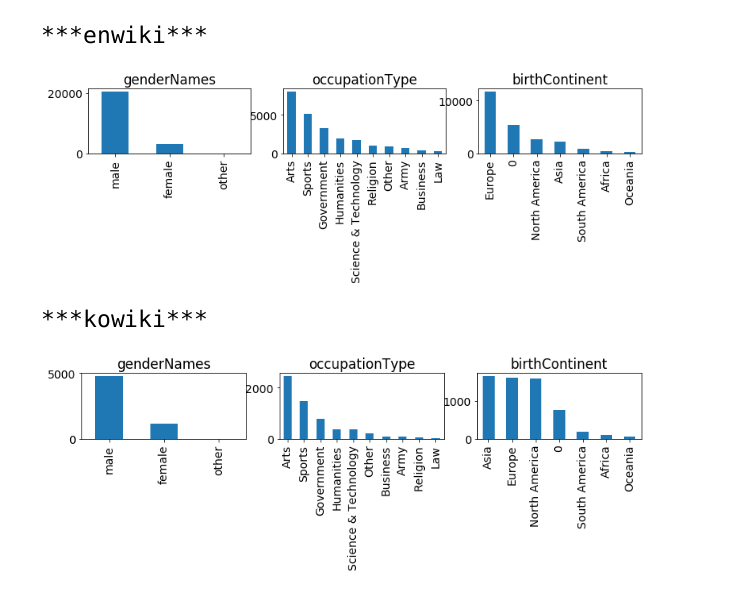
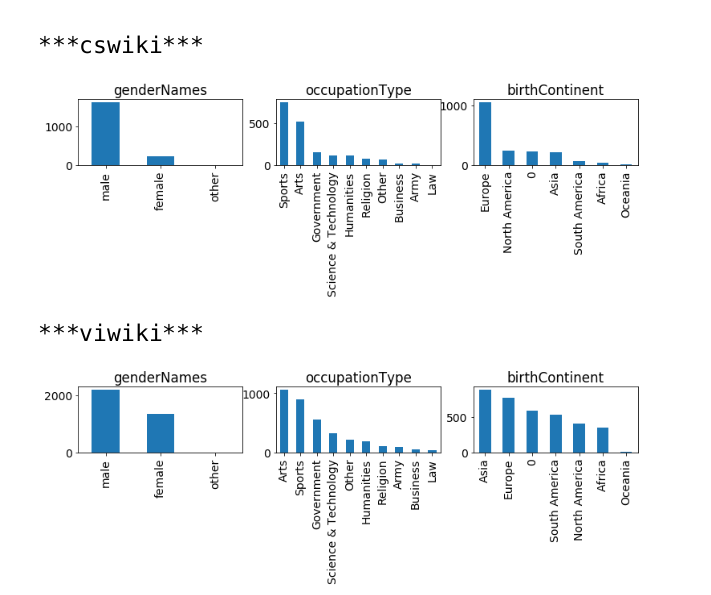
For a set of article titles lacking any images, list one or more image suggestions from Commons, perhaps ranked in some order. Perhaps this could be done for 100 random unillustrated articles in each of these wikis: enwiki, frwiki, arwiki, kowiki, cswiki, viwiki.
We can take these suggestions and ask native speakers to evaluate whether they are good matches, and then have a sense for the accuracy of our approach.
It would also be valuable to know for how many articles in each of those wikis suggestions can be made, so we know how deep the pool of suggestions might be in a given wiki.