Problem
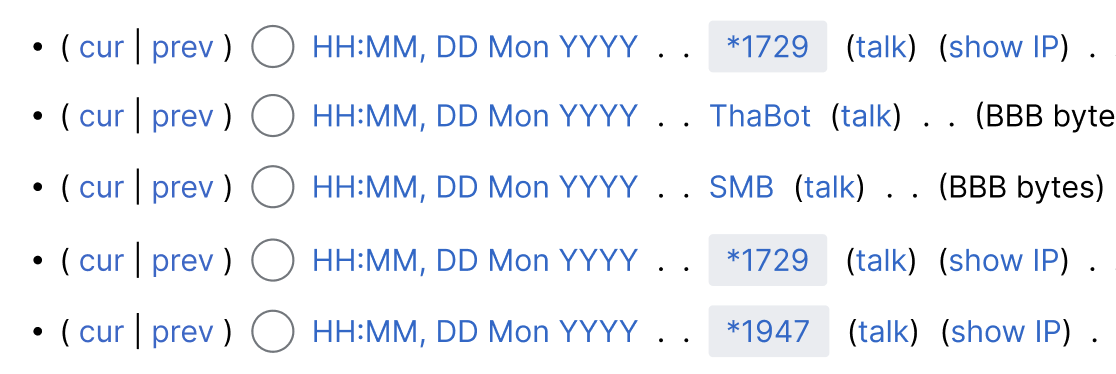
There is an old bug T14974 in MediaWiki that breaks templates, variables, parser functions etc that accept usernames for input which begin with characters that have a special predefined “start-line” formatting. This includes the character * which is why it is problematic for IPM since our choice of temp usernames is beginning them with an asterisk. For these characters, the software forces a newline when the character is encountered.
The exact way it breaks is as follows -
Say I have a template like this that inputs a username as a parameter:
[[User:{{ucfirst:*Unregistered 1}}]]
However the output will look like -
[[User: * *Unregistered 1]]
Sandbox for demo.
Here’s an on-wiki discussion that includes some examples of the problems here.
Preferred solution:
We pick a different character that seems more viable. If we want to do this, we can look through our past analysis on the usage for different characters. I will note that there are others besides * that suffer from the same bug - # : {| ;. Also, = has been called out as a bad character choice because it acts as an assignment operator inside functions/templates. See full list below.
Previously considered alternate solution
We stick to the * and expect the bug to be fixed. The problem with this approach is that the bug has existed for so long that a number of templates/functions etc have started relying on the bug and working around it. Fixing the bug will break these. We will need to work with the communities to modify these. Even though this feels like the right approach, it will require a lot of effort and time to help the communities make the changes and also require an unknown amount of work from the parsing team to actually fix the bug.
Prefix options (in order of preference)
| Character | Count | Notes | Can it be used as a temp username prefix? |
|---|---|---|---|
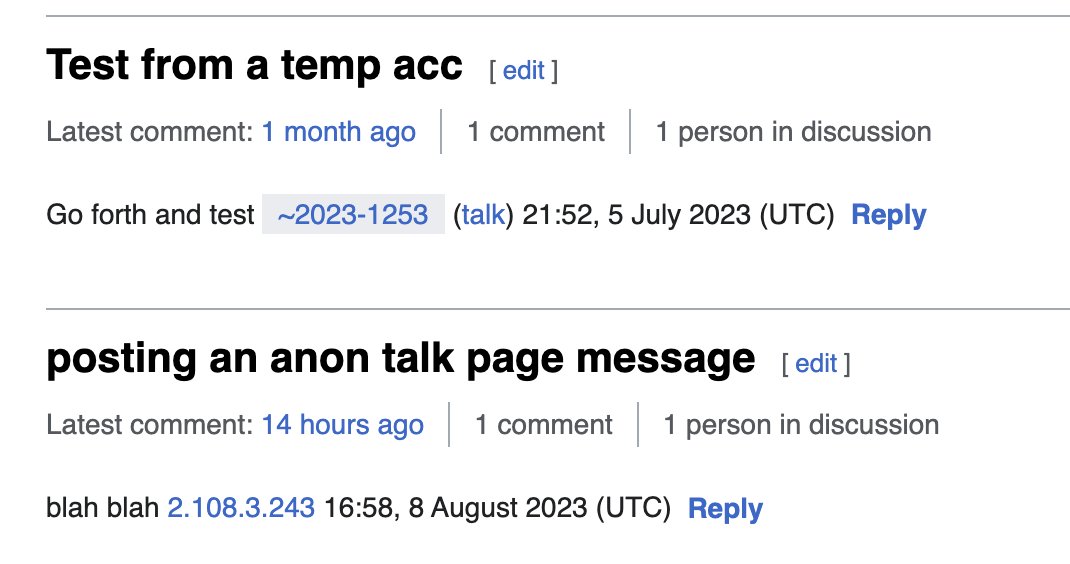
| ~ | 1160 | Previously used in a suffix to indicate account renamed in SUL unification | |
| - | 10387 | ||
| ^ | 1409 | ||
| ! | 2715 | ||
| \ | 217 | ||
| 2XXX (year as prefix) | |||
Ruled out prefix options
| Character | Known issues | Can it be used as a temp username prefix? |
|---|---|---|
| % | Special character in URLs, may cause compatibility issues with gadgets | No |
| & | Special character in URLs, may cause compatibility issues with gadgets | No |
| ( | Would probably be very annoying when switching between LTR and RTL wikis | No |
| ) | Would probably be very annoying when switching between LTR and RTL wikis | No |
| * | T14974 | No |
| + | Special character in URLs, may cause compatibility issues with gadgets | No |
| / | Invalid in usernames | No |
| : | T14974; Currently invalid in usernames (InvalidUsernameCharacters) | No |
| ; | T14974 | No |
| < | Invalid in titles | No |
| = | Acts as an assignment operator within templates & functions; Currently invalid in usernames (InvalidUsernameCharacters) | No |
| > | Used as the default interwiki prefix when importing pages; Currently invalid in usernames (InvalidUsernameCharacters); Invalid in titles | No |
| ? | Special character in URLs, may cause compatibility issues with gadgets | No |
| @ | Used in the reply tool on talk pages to mention other users; Used as special syntax when setting user rights cross-wiki; Currently invalid in usernames (InvalidUsernameCharacters) | No |
| { | Invalid in titles | No |
| pipe | Invalid in titles | No |
| } | Invalid in titles | No |
| — (M dash) | Hard to type | No |
| # | T14974; Invalid in titles | No |
| [ | Invalid in titles | No |
| ] | Invalid in titles | No |
| _ | Invalid in titles (underscores become spaces, leading spaces are removed) | No |
| " | Unbalanced quotes could throw off users | No |
| $ | Could be interpreted as currency; May not be easily typed by users in different locales | No |
| ' | Unbalanced quotes could throw off users | No |
| , | Too small | No |
| . | Too small | No |
| ` | Unbalanced quotes could throw off users | No |