What?
Before we can switch VE to using Parsoid in MW (rather than going through RESTbase), we need to ensure that parsoid output for the page is present in the ParserCache.
Context
Currently, RESTbase will be notified when a page needs to be re-parsed, and it will then call the page/html endpoint exposed by the Parsoid extension to get the updated HTML. These requests are currently routed to the Parsoid cluster. At this point, this HTML will be written to the parser cache.
In the future, we want to turn of caching in RESTbase. When we do this, we need another mechanism to be in place that ensures we have up to date parsoid renderings of each page in the parser cache. This can be done by setting WarmParsoidParserCache to true in $wgParsoidCacheConfig, which will cause a ParsoidCachePrewarmJobs to be scheduled when a page need to be re-rendered.
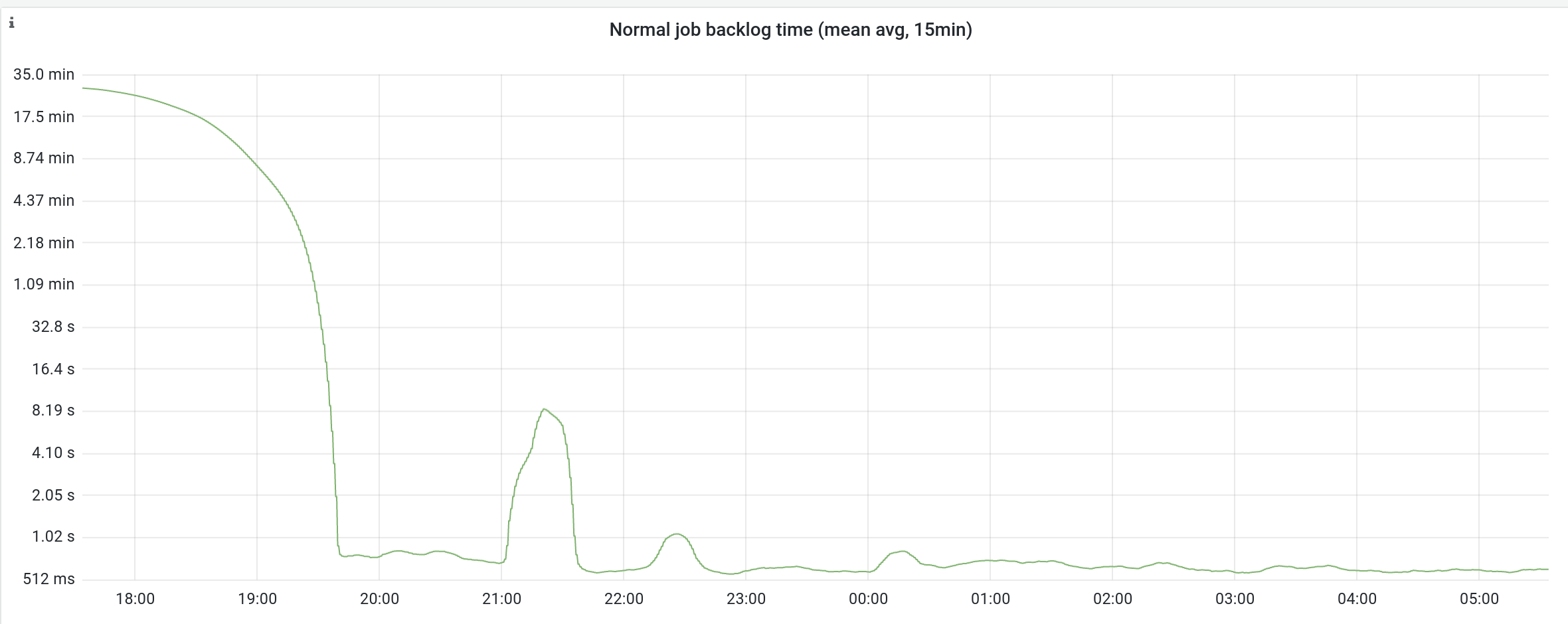
These jobs are currently only enabled on testwiki and mediawikiwiki, because we did not want to overlaod the JobRunner cluster. The purpose of this job is to track all work needed to enable the ParsoidCachePrewarmJobs.
The request flow is as follows: mw-> eventgate-main -> kafka -> changeprop-jobqueue -> jobrunners
How?
Per @Joe's suggestion:
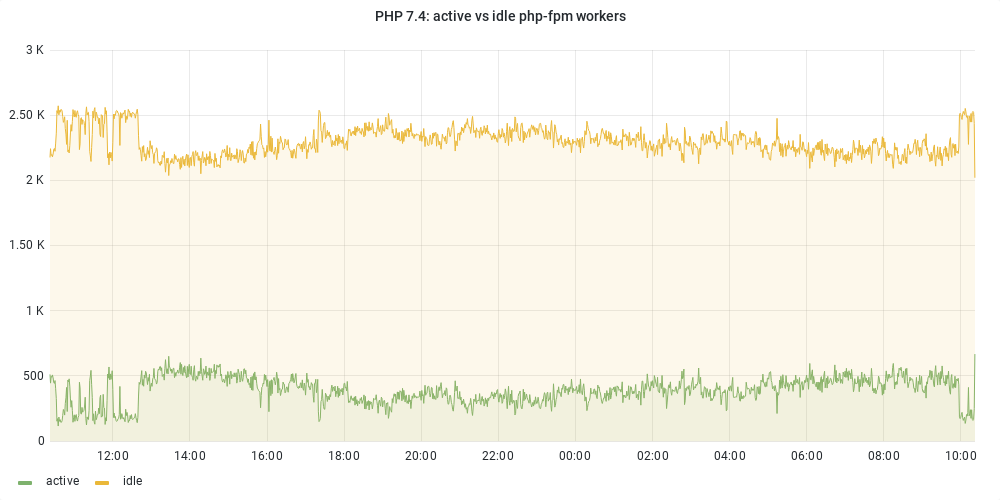
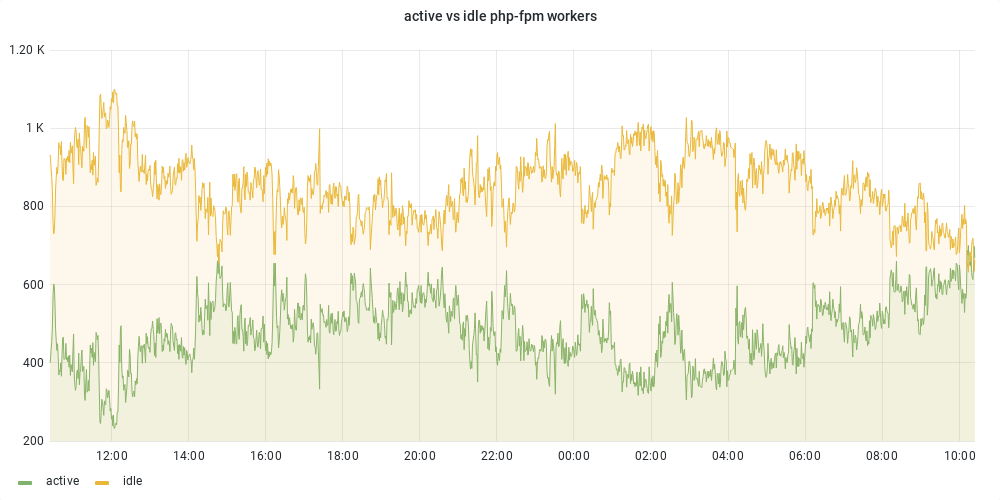
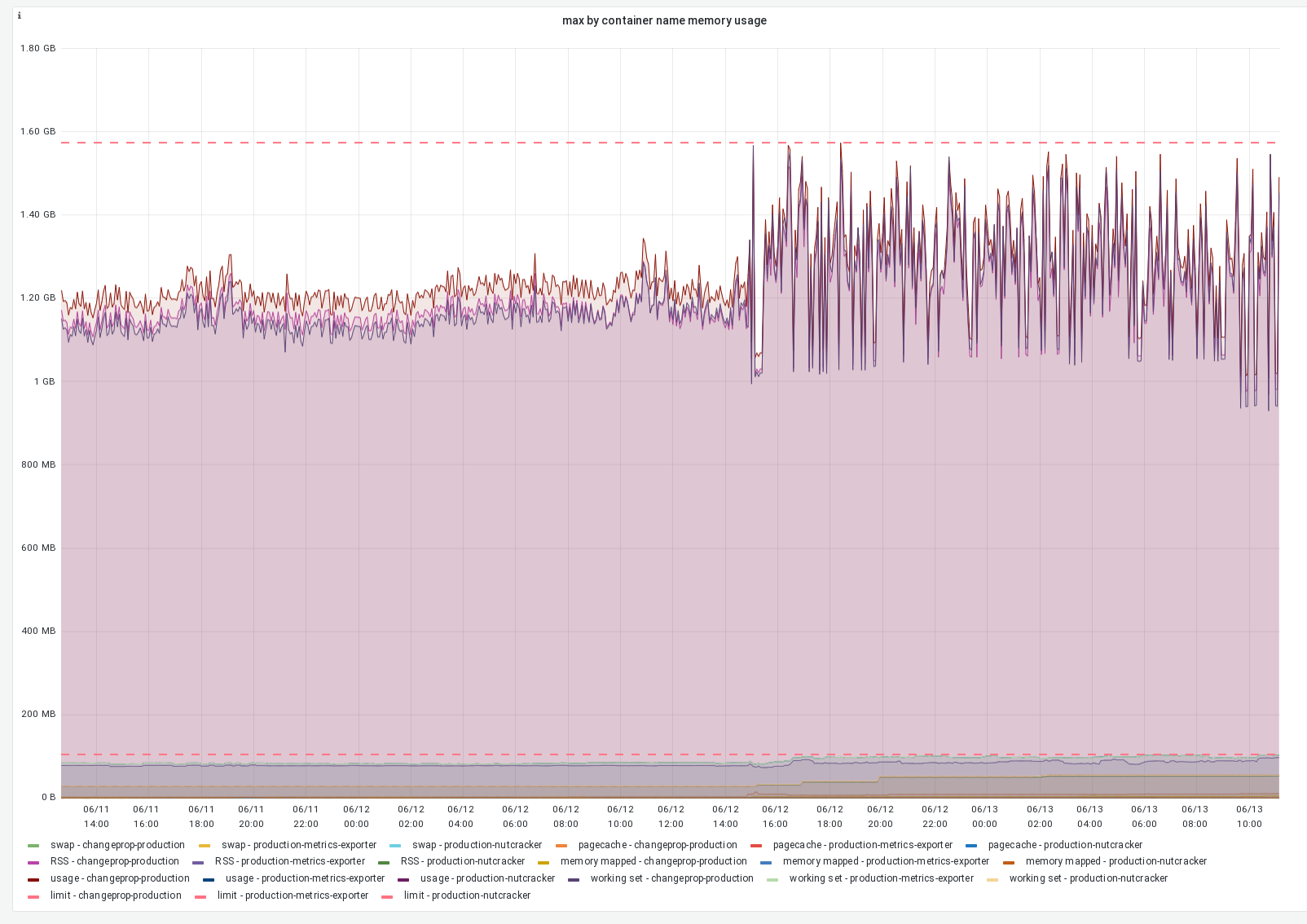
- Increase the memory limit for the jobrunner cluster in mediawiki-config
-
Move a few servers from the parsoid cluster to the jobrunner cluster (in puppet)[Not needed pre-emptively] - Enable the jobs for wikis in batches, with SRE assistance. Possibly move more parsoid nodes to jobrunners if needed
- For each batch, configure restbase to disable the caching for that wiki - basically only send out the purges for its urls.
- rinse, repeat until nothing is left
At this point, the scope of this specific task is complete. The remainder is here just to complete the list.
Decide how we'll send the purges to the CDN for the restbase urls. My favourite option if we don't want to set up a complete system now would be to generate the purges when the warmup job is completed.
- Stop sending requests to restbase from change-propagation for parsoid.
- Move the requests for parsoid from all sources to bypass restbase (via the api gateway restbase compatibility layer)
- Kill the restbase storage for parsoid
Alternative steps (elegant but riskier)
Basically instead of point 1-4 of the previous procedure:
- Make changeprop handle these jobs separately.
- Either submit them to the parsoid cluster as jobs (this requires some SRE work) or (preferred) just calling the URL for the rendering of the page directly (this requires probably some work on changeprop)
- Once the parsercache is sufficiently warm, disable restbase caching for a batch of wikis, only keeping the purges emitted.
Dashboards to monitor
- https://grafana-rw.wikimedia.org/d/OxxOv5K4k/ve-backend-dashboard?orgId=1&refresh=30s
- https://grafana.wikimedia.org/d/CbmStnlGk/jobqueue-job?orgId=1&var-dc=eqiad%20prometheus%2Fk8s&var-job=parsoidCachePrewarm&from=now-12h&to=now
- https://grafana-rw.wikimedia.org/d/wqj6s-unk/jobrunners?orgId=1&from=now-6h&to=now