As an editor I want to enter values for Properties with datatype monolingual text in any available language in order to record complete data.
Problem:
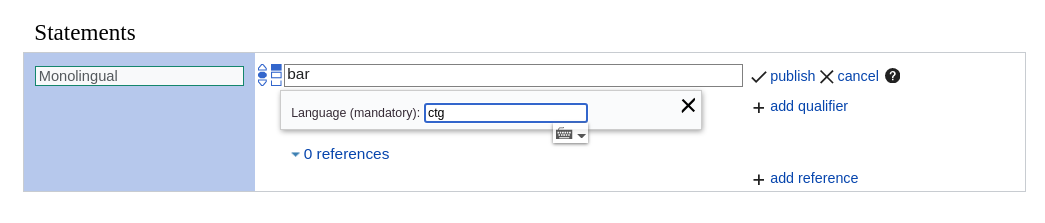
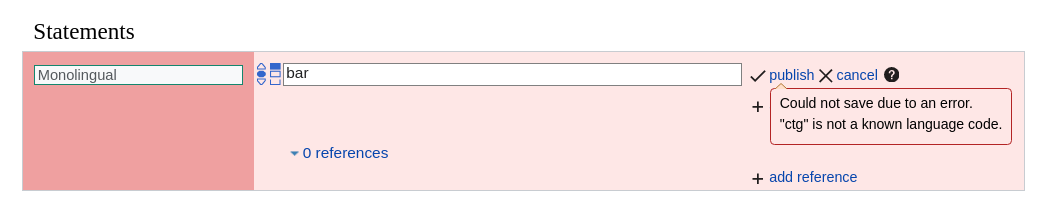
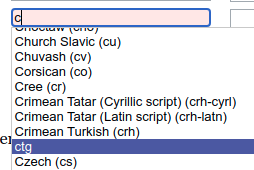
The language suggester for monolingual text does not show some accepted languages in its dropdown despite it being possible to save statements with these values. This is confusing for users.
Example:
You can store statements for monolingual text values with language code cho but it is not shown in the dropdown when entering the language code.
Screenshots/mockups:
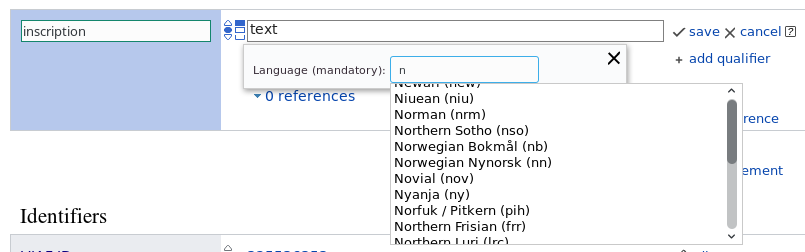

BDD
GIVEN a special language code
WHEN entering a monolingual text value
AND entering the special language code in the language field
THEN it is recognized
AND shows up in the suggester
Acceptance criteria:
- all accepted language codes show up in the dropdown for monolingual text values
- at least the language code is displayed, if possible the autonym (the language name in the language itself) as well or ideally the translated language name + code